Intro
I have been exploring serverless platforms in various guises for some time now. I won’t name any names, but I’ve played around with most of the various major platforms.
The common thing that I noticed when using other platforms was that I needed to either wrap my code in a vendor specific DSL or language, or that I needed to import libraries from the vendor.
As a developer, that didn’t really float my boat and, was difficult to get up and running as existing code needed to be refactored and so on.
So I decided to write my own serverless platform.
This series of blogs describes the architecture, the code and, the how and why as well as the problems I have hit along the way in bringing this to life.
Why
My dissatisfaction led me to think long and hard about what I wanted from a serverless platform. I came up loosely with the following list.
- I want to upload my code only and not worry about infrastructure components.
- I do not want to build container images.
- I do not want to modify my code at all (this includes importing libraries)
- I want to be able to deploy fast.
I took this loose list and thought about how I could make this happen.
Genesis
There is an open source project by NGINX called NGINX Unit. This project is interesting in that it provides a complete application server. As an application server, Unit can run my code without major changes.
Unit has a REST-based configuration DSL, can listen over a network and can automatically run my code.
Info
Project Tetsuo was born
Vision
My vision is simple. I want a full serverless platform that allows me to point at a git repository and, deploy my code without any further interaction or changes.
Architecture
Unit provides a lot in terms of having a way to run my applications.
I still need some more components to bring my vision to life.
Unit today
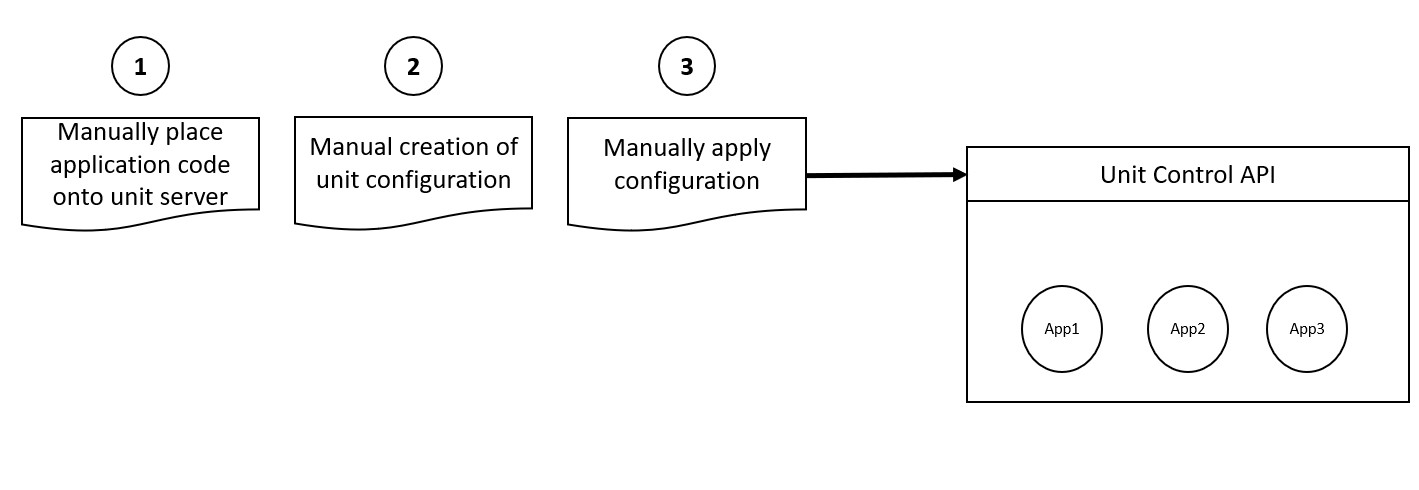
Today, Unit operates entirely manually. The process for configuring Unit is as follows:
- Manually place application code onto the Unit server.
- Manually craft a unit configuration that matches your application type.
- Manually apply the configuration to the Unit server.
This is fantastic and is very flexible. It allows me as a developer to completely customise my application and deployment.
It does require a number of manual steps though which does not quite meet my vision.
Additional API’s
In order to meet my vision, I have written two applications that run on the Unit server. Each application is an API that I can call or orchestrate via an external system. That can be either a Continuous Integration tool, or it can be a user interface.
The idea here is simple - have as few manual steps as possible in order to deploy an application.
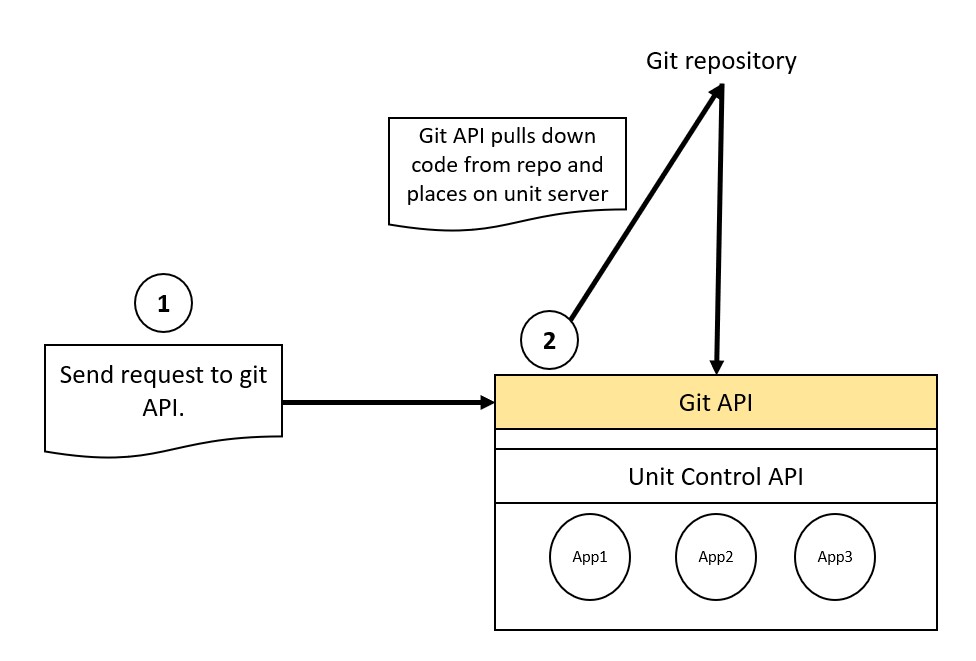
Git API
The git API is responsible for receiving a git URL, and a branch. This API is responsible for performing a git clone, if the repository does not exist on the Unit server, or for performing a git pull if the repository does exist on the Unit server.
This way, application code can be updated and pulled down to the Unit server with a single call.
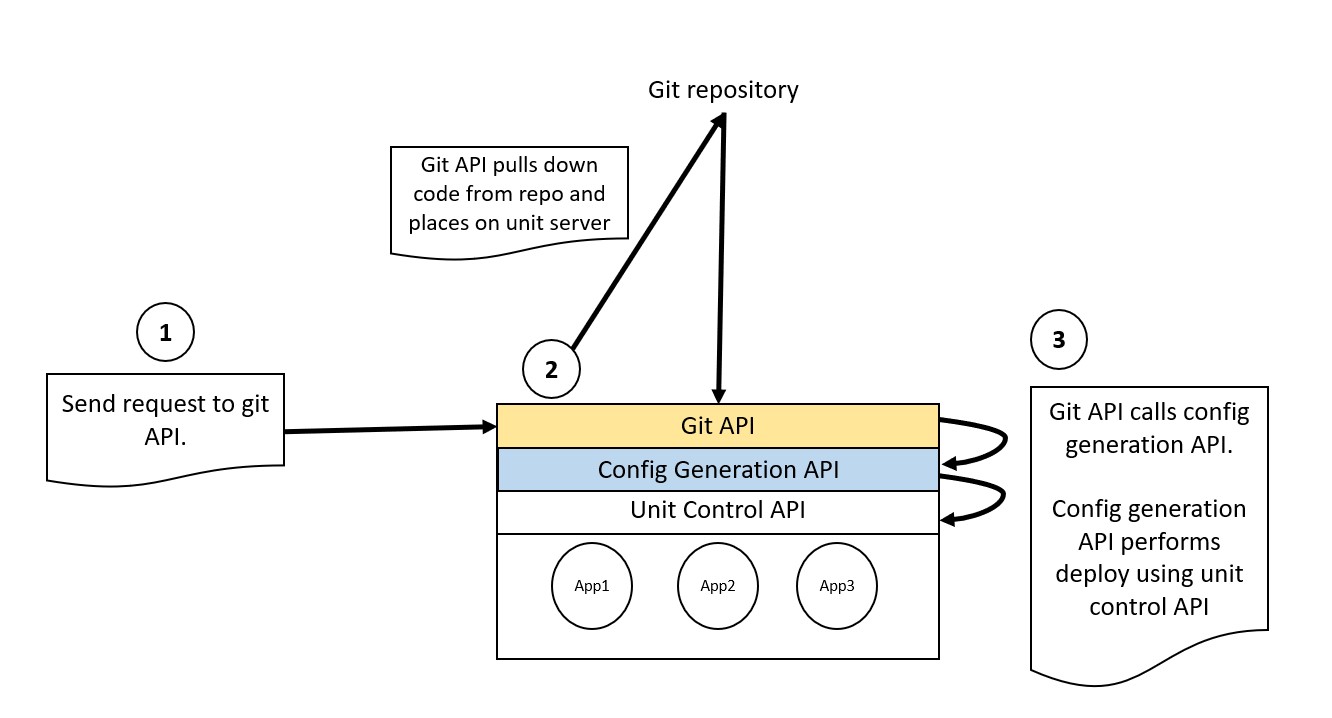
Config API
The config API is responsible for receiving a path that represents where the application has been placed on the Unit server. In my case this is a standardised location that the git API uses. While the API receives a location in the form of a directory, it has been designed primarily for flexibility.
The config API generates a standardised Unit configuration that can be used to make the deployment of the application easier.
Note
The configuration is opinionated
What does this look like?
Today, there is no user interface, so two single API calls will deploy an application onto my Unit server.
I can deploy my code, only my code, and it’s fast. There is no artefact to build, no container to deploy, just my raw code, and it runs.
Note
Deploy code not containers
Where to from here?
At the moment, this is a continuing work in progress. I am working on a front end to facilitate deployment, and already have a configuration sync API as a minimum viable product that will synchronise configurations between Unit servers.
These will be discussed separately in subsequent posts.